数据优化是一个大学问,本节部分内容来自百度
一、模板标签
模板标签写法不合理时会导致cpu占用过高,网站缓慢,不推荐使用的标签
module=all 全模块查询严重影响速度 related 相关标签,按关键词查询影响速度 order=rand 避免这种随机排序,严重影响速度
二、创建索引
最简单也是最常用的优化就是查询。因为对于CRUD操作,read操作是占据了绝大部分的比例,所以read的性能基本上决定了应用的性能。对于查询性能最常用的就是创建索引。经过测试,2000万条记录,每条记录200字节两列varchar类型的。当不使用索引的时候查询一条记录需要一分钟,而当创建了索引的时候查询时间可以忽略。但是,当你在已有数据上添加索引的时候,则需要耗费非常大的时间。我插入2000万条记录之后,再创建索引大约话费了几十分钟的样子。
创建索引的弊端和场合。虽然创建索引可以很大程度上优化查询的速度,但是弊端也是很明显的。一个是在插入数据的时候,创建索引也需要消耗部分的时间,这就使得插入性能在一定程度上降低;另一个很明显的是数据文件变的更大。在列上创建索引的时候,每条索引的长度是和你创建列的时候制定的长度相同的。比如你创建varchar(100),当你在该列上创建索引,那么索引的长度则是102字节,因为长度超过64字节则会额外增加2字节记录索引的长度。
1、为搜索字段建索引
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么,请为其建立索引吧。
2、千万不要 ORDER BY RAND() 和order=rand标签
想打乱返回的数据行?随机挑一个数据?真不知道谁发明了这种用法,但很多新手很喜欢这样用。但你确不了解这样做有多么可怕的性能问题。
如果你真的想把返回的数据行打乱了,你有N种方法可以达到这个目的。这样使用只让你的数据库的性能呈指数级的下降。这里的问题是:MySQL会不得 不去执行RAND()函数(很耗CPU时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了Limit 1也无济于事(因为要排序)
3、在Join表的时候使用相当类型的例,并将其索引
如果你的应用程序有很多 JOIN 查询,你应该确认两个表中Join的字段是被建过索引的。这样,MySQL内部会启动为你优化Join的SQL语句的机制。
而且,这些被用来Join的字段,应该是相同的类型的。例如:如果你要把 DECIMAL 字段和一个 INT 字段Join在一起,MySQL就无法使用它们的索引。对于那些STRING类型,还需要有相同的字符集才行。(两个表的字符集有可能不一样)
4、对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
5、应尽量避免在 where 子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。
6、任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
三、读写分离
用两台或者多台主机做集群,一般是一写多读(一台mysql只写入,剩下的用来读取,写入的数据要实时的从写库同步到读库)这个配置起来也比较简单,唯一要说的是代理插件的选择,推荐360开源的atlas,用法很简单,实际使用中也没有太多bug。
四、数据表分区
什么是分区?
分区和分表相似,都是按照规则分解表。不同在于分表将大表分解为若干个独立的实体表,而分区是将数据分段划分在多个位置存放,分区后,表还是一张表,但数据散列到多个位置。
另外分区也可以分为两种:
垂直分区和水平分区
水平分区(Horizontal Partitioning)这种形式分区是对表的行进行分区,所有在表中定义的列在每个数据集中都能找到,所以表的特性依然得以保持。
垂直分区(Vertical Partitioning)这种分区方式一般来说是通过对表的垂直划分来减少目标表的宽度,使某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应的行。
五、MYSQL缓存配置
在MySQL中有多种多样的缓存,有的缓存负责缓存查询语句,也有的负责缓存查询数据。这些缓存内容客户端无法操作,是由server端来维护的。它会随着你查询与修改等相应不同操作进行不断更新。通过其配置文件我们可以看到在MySQL中的缓存:
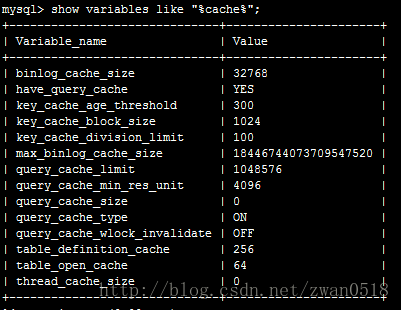
在这里主要分析query cache,它是主要用来缓存查询数据。当你想使用该cache,必须把query_cache_size大小设置为非0。当设置大小为非0的时候,server会就会缓存每次查询返回的结果,到下次相同查询server就直接从缓存获取数据,而不是再执行查询。能缓存的数据量就和你的size大小设置有关,所以当你设置的足够大,数据可以完全缓存到内存,速度就会非常之快。
但是,query cache也有它的弊端。当你对数据表做任何的更新操作(update/insert/delete)等操作,server为了保证缓存与数据库的一致性,会强制刷新缓存数据,导致缓存数据全部失效。所以,当一个表格的更新数据表操作非常多的话,query cache是不会起到查询提升的性能,还会影响其他操作的性能。